
Introduction
Crank is an open system for testing and validating workflows, apps, and experiences that are defined, configured, and built in SaaS platforms, rather than in code.
This documentation will eventually be merged into crank.run, but for now, if you're looking for details on how to build a Cog. You've found the right place!
Looking for overall details about Crank? Visit crank.run
Concepts
What's in a Cog?
The gRPC interface for a Cog:
syntax = "proto3";
service CogService {
rpc GetManifest (ManifestRequest) returns (CogManifest) {}
rpc RunStep (RunStepRequest) returns (RunStepResponse) {}
rpc RunSteps (stream RunStepRequest) returns (stream RunStepResponse) {}f
}
A Cog is like an assertion library for a remote system. Cogs implement an API, ensuring interoperability with other Cogs. The Cog API is built on gRPC (a modern, open source, language-agnostic RPC framework) and uses protocol buffers as both the interface definition language and the data serialization format. In gRPC parlance, a Cog is a gRPC server that implements the Cog Service interface. Crank is (among other things) a gRPC client that knows how to communicate with Cogs.
The Cog Service interface consists of just 3 methods:
- GetManifest, a method that returns metadata about the Cog sufficient for Crank or other clients to execute steps and authentication details in the expected format.
- RunStep, a method that executes a single step or assertion with a given
set of data (conforming to expectations set forth in
GetManifest), and responds with the result of the assertion. - RunSteps, similar to the above method, but executes a stream of steps and responds with a stream of results. Intended for scenarios where a series of steps are intended to run within a shared context (e.g. sharing an auth session, browser session, etc)
More details on the request and response types for these methods can be found in the protocol buffer messages reference section. For a complete introduction on gRPC and protocol buffers, see this guide.
Authentication
The Protocol Buffer Message definition for a CogManifest
message CogManifest {
// Example: automatoninc/eloqua
string name = 1;
// Example: Eloqua
string label = 5;
// Example: 1.0.0
string version = 2;
repeated StepDefinition step_definitions = 3;
repeated FieldDefinition auth_fields = 4;
}
Crank is intended to help test and validate SaaS software configurations and other remote systems, necessitating a standard way to pass authentication details from the test runner to each underlying assertion library. Crank does this flexibly, ensuring compatibility with any authentication scheme.
In gRPC terms, authentication details are passed from client to server using
gRPC metadata. Each call to a Cog's RunStep or RunSteps method includes
any number of authentication fields, passed on the call's metadata.
Cogs declare the authentication details they need in their manifest on the
auth_fields property in the form of FieldDefinition messages.
As an example, if a Cog were to be implemented using an underlying API client
library that used HTTP Basic Authentication to connect to a remote system, the
Cog's manifest would declare two auth_fields field definitions: one with a
username key, and another with a password key, that the Cog could parse
and apply to the underlying API client on each RunStep(s) method call.
What's in a Step (Definition)
The Protocol Buffer Message definition for a StepDefinition
message StepDefinition {
// Example: FillOutEloquaForm
string step_id = 1;
// Example: Fill Out an Eloqua Form
string name = 2;
// See protocol buffer message reference for enum values.
Type type = 5;
// Example: fill out Eloqua form (?<eloquaFormName>.+)
string expression = 3;
// See below for an abridged FieldDefinition definition
repeated FieldDefinition expected_fields = 4;
}
One of the most important properties on a Cog's manifest is a list of
StepDefinition messages. Each step definition represents an assertion or
action that the Cog can make against the system that the Cog interfaces with.
A step definition consists of three string properties, used to identify the step in various contexts, as well as a type, and a list of fields that the Cog expects when the step is executed.
- The step_id is a machine identifier that Crank and other Cog clients use
to identify a step. When
RunSteporRunStepsmethods are called, this step ID will be passed, and your Cog will need to use it to properly dispatch its step logic. An example step ID isFillOutEloquaForm, which could correspond to a class name, method name, or some other identifier in your own Cog code. - The name is a human-friendly identifier that Crank and other Cog clients
will use to identify the step to end-users, e.g.
Fill Out an Eloqua Form. - The type denotes whether the step is like an assertion or validation (which explicitly has a failure state and which is idempotent in nature), or like an action (which has no failure state, and whose intention is to set up or otherwise establish pre-conditions for a scenario).
- The expression is an ECMAScript-compatible regular expression used to
identify and evaluate this step in cucumber-like scenario files, as shown in
the introduction of this documentation. This regex should use named capture
groups so that Crank can pass back step data to your Cog using the expected
field names, e.g.
fill out Eloqua form (?<eloquaFormName>.+). These expressions are evaluated in the context of multiple cogs, so it's important that they be globally unique and unambiguous (the aforementioned example achieves this by including the name of the system,Eloqua, in the regex).
For a complete reference on the StepDefinition protocol buffer message, see the corresponding protocol buffer message reference section.
An abridged Protocol Buffer Message definition of a FieldDefinition
message FieldDefinition {
// Example: eloquaFormName
string key = 1;
// See protocol buffer message reference for enum values.
Optionality optionality = 2;
// See protocol buffer message reference for enum values.
Type type = 3;
// Example: HTML form name of the Eloqua form
string description = 4;
}
Field Definitions
Accompanying each step definition is an optional list of field definitions.
These represent the expected data and their schema when passed in on the Cog's
RunStep or RunSteps methods. In the example in this section, you would
expect two fields: an eloquaFormName and eloquaFormData, an arbitrary map
of field/value pairs containing HTML form submission data.
- The key is a string that will be used to key the corresponding value when a value is passed to the Cog during step execution.
- The description is used to identify the field to end-users of Crank and other Cog clients.
- The optionality indicates whether or not the field is required for execution.
- And the type indicates the expected form of data and is used by Crank and other Cog clients to vary the user interface and perform validation of test data before passing it to your Cog.
For a complete reference on the FieldDefinition protocol buffer message, see the corresponding protocol buffer message reference section.
Docker
An example Dockerfile for a node.js Cog
FROM mhart/alpine-node:12
WORKDIR /app
COPY . .
RUN npm install && npm prune --production
ENV HOST 0.0.0.0
ENV PORT 28866
EXPOSE 28866
ENTRYPOINT ["npm", "start"]
Although it's possible to write a Cog in any language that supports gRPC, it's important to be able to easily install and operate Cogs without having to download any dependencies or prerequisites. Working Cogs are packaged up as docker images, which Crank can download, install, and run.
Cogs as docker images need only conform to the following specification:
- HOST: the Cog should bind its gRPC server to the host specified in the
HOSTenvironment variable. We recommend0.0.0.0as a good default that supports local development. - PORT: the Cog should bind its gRPC server to the port specified in the
PORTenvironment variable. We recommend28866as a good default that supports local development. - SSL/TLS Support: by default, Crank communicates with all Cogs without any
encryption; when communication is between processes on a single machine (as
is the case with Crank), SSL is not necessary. However, if you intend to run
your Cogs in a distributed manner (e.g. over a network), support for SSL/TLS
is provided through details injected via environment variables:
- SSL_ROOT_CRT: a base64-encoded PEM certificate representing the root or CA cert.
- SSL_CRT: a base64-encoded PEM cert
- SSL_KEY: a base64-encoded PEM private key
Note, you can test SSL support in your Cogs by passing the --use-ssl flag to
any sub-command used to run steps. See this documentation for details on
gRPC SSL/TLS support.
We recommend using the lightest-weight base images possible: base images that support your language of choice, derived from Alpine linux are ideal.
Building Cogs
The following is a guided walkthrough of how to build a Cog using tooling provided by Crank. If you're already familiar with gRPC, you may wish to bypass this walkthrough and just look at the protocol buffer reference and concepts sections... But that path is not for the faint of heart.
First thing's first: install crank if you haven't already!
Next, be sure you've got all of the tooling and frameworks you use in your language of choice* (e.g. a recent version of node.js / npm).
Note: this walkthrough currently only supports typescript, but in the future, we hope to provide boilerplate for a variety of languages. If you're interested in contributing scaffolding for another language, let us know!
Scaffolding a Cog
Recommended steps for scaffolding your first Cog
# 1) Create working directory.
mkdir /path/to/hello-world-cog
cd /path/to/hello-world-cog
# 2) Run the crank cog:scaffold command and answer prompts
crank cog:scaffold --include-example-step
1) Before you begin, you'll want to set up a working directory where your Cog code will reside. Anywhere will do, but somewhere near the other code you work on is probably best.
2) Once your working directory is sorted, you can use Crank to generate boilerplate code necessary to get a working Cog up and running. The command to run is
crank cog:scaffold, which will interactively prompt you for details about your Cog, and then populate the current working directory with the starting point for your cog's code.
You will be prompted for the following details:
- Service Name: In order to derive a name and label for your Cog, Crank will ask what service your Cog will interface with (e.g. Salesforce).
- Docker Hub Organization Name: Crank will also ask for your organization's
name on Docker Hub. Combined, these details form the Cog's name, for example:
automatoninc/salesforce. If your organization does not have a Docker Hub presence, or you have no intention of releasing your Cog to the wider world, you can just enter the default (automatoninc). - Language: The programming language that the generated code will be in (currently, only typescript is supported, but pull requests for additional languages are welcome).
- Example Step Inclusion: Whether or not the generated code will include an
example step. If this is your first time, we recommend you select
y, as the rest of the walkthrough assumes you've done this. You can specifynwhen running this Cog later, once you're familiar with the generated code.
Installing the Cog
3) Crank will now generate the boilerplate code and attempt to install any dependencies or prerequisites automatically on your behalf.
4) Next, Crank will attempt to install the newly generated Cog by running a variation of
crank cog:installon your behalf.
In order to demonstrate the use of authentication fields, the generated Cog declares a "User Agent" field in its manifest. Crank will automatically ask for authentication details at install-time, so you will be prompted for such a value during this Cog installation step. You can enter any string or skip this step.
Crank persists Cog authentication details to disk for convenience. When a Cog is uninstalled, its associated authentication details are also removed.
Testing the Cog
# 5) Run this (or similar) command to test your Cog
crank cog:step automatoninc/hello-world
5) If all went according to plan, you should see a recommendation on a command to run in order to test your new Cog. The
crank cog:stepcommand allows you to select a single step to run for a given Cog. Because you just generated this Cog, there will only be one step to choose from:Assert that a field on a JSON Placeholder user has a given value.6) As the name of the step implies, the generated Cog and example step interface with the JSON Placeholder API, validating that a specified field on the API's user object has a specific value for the user with the given email address. When you run
crank cog:step, you will be prompted to enter values for these fields.
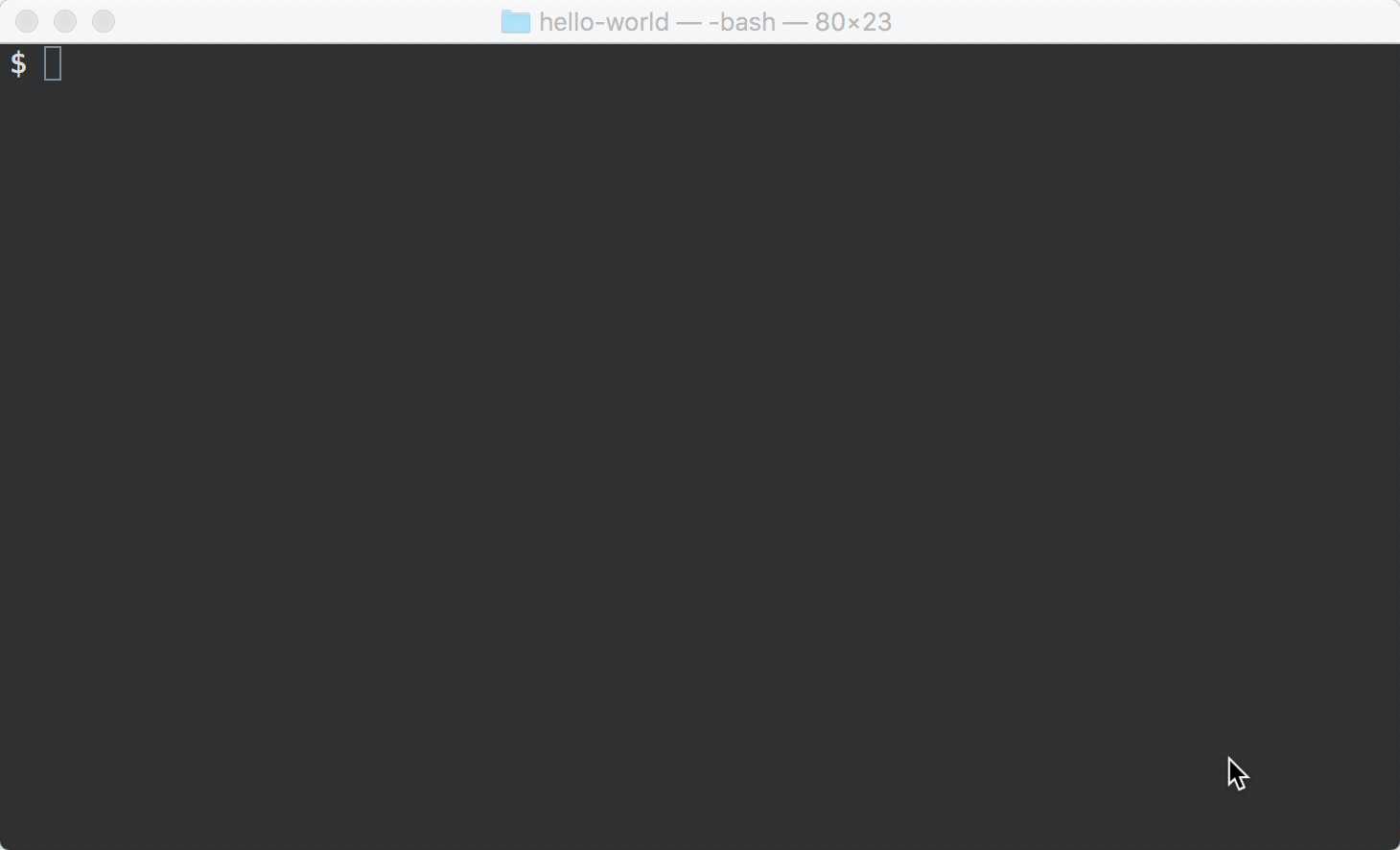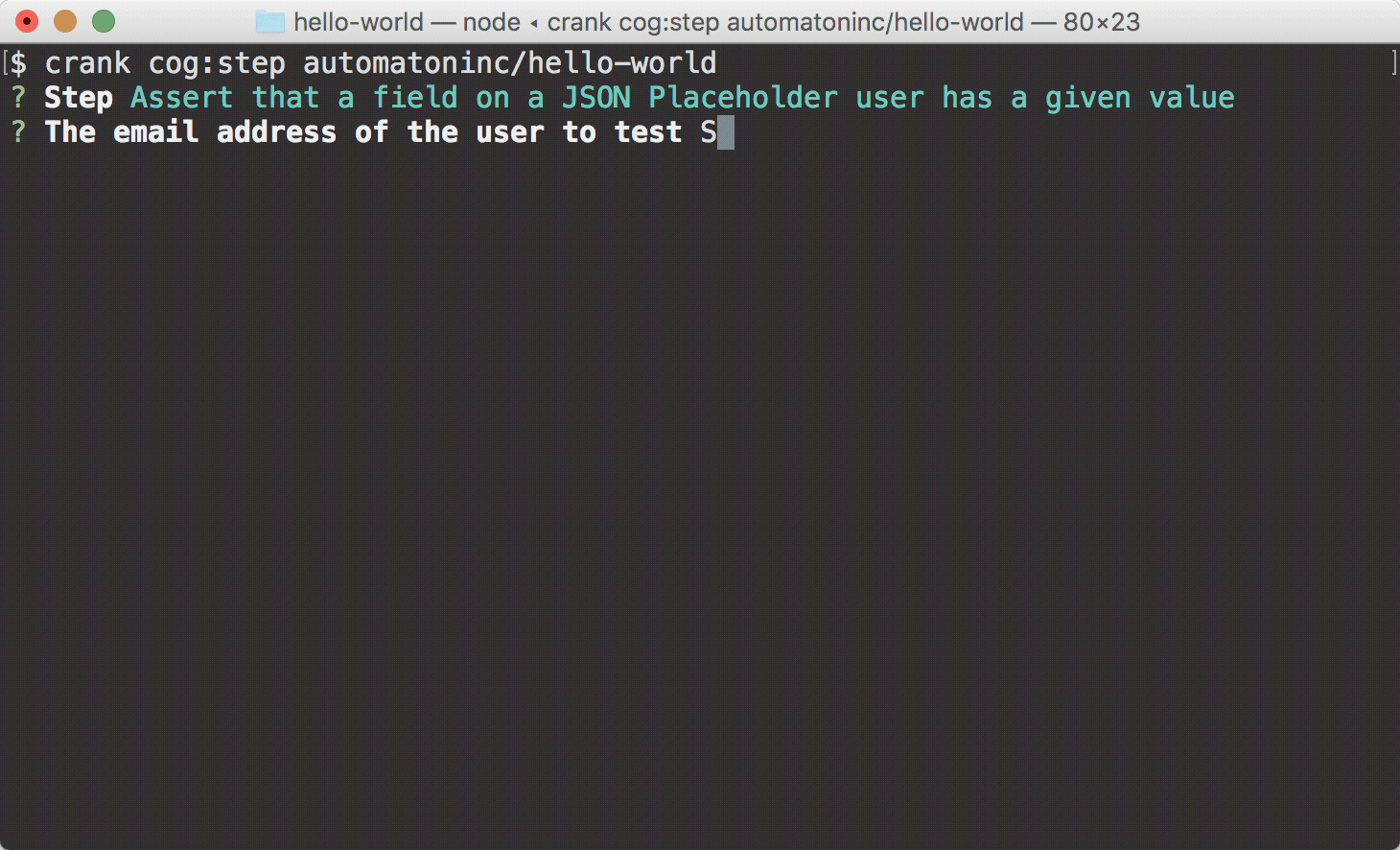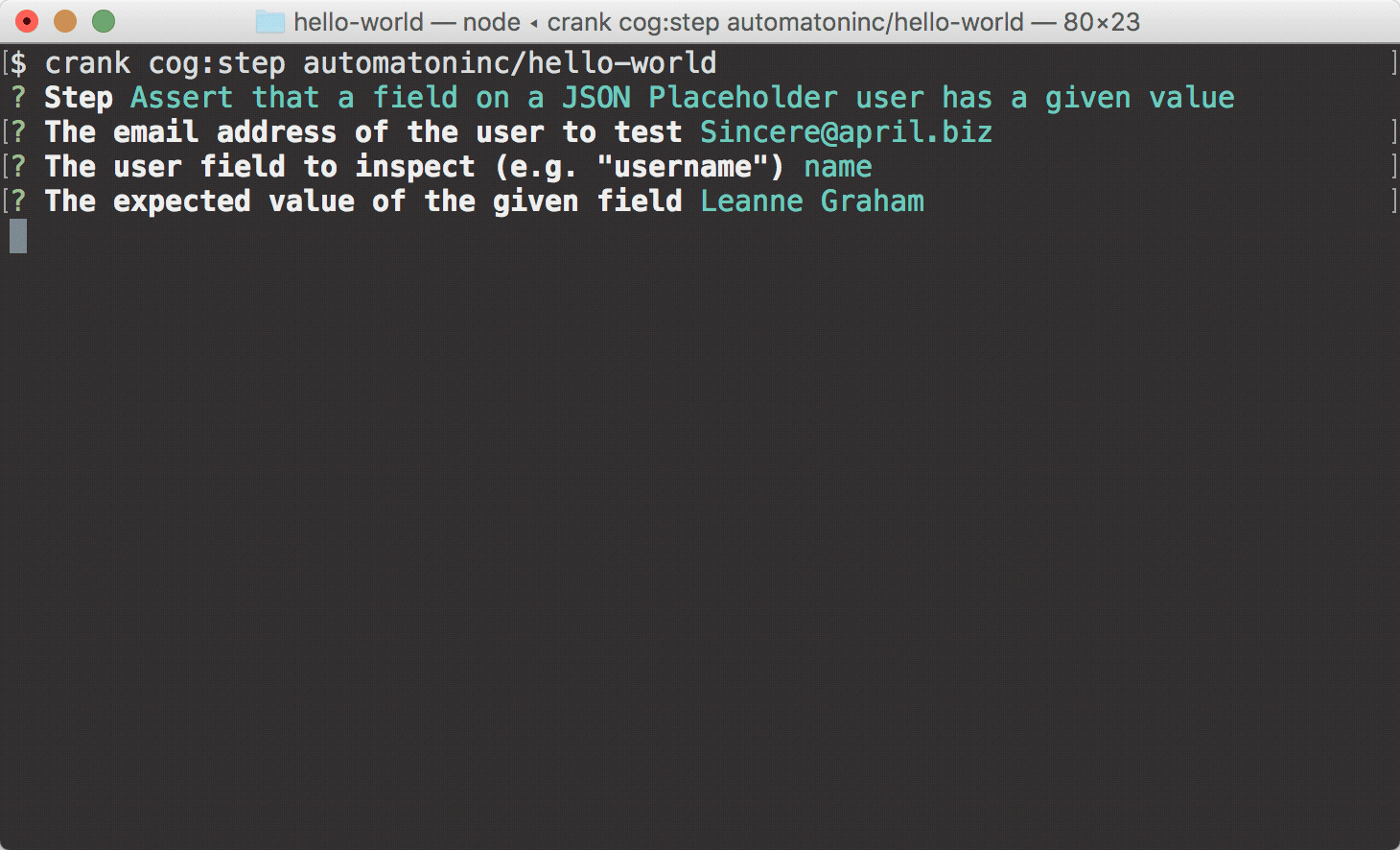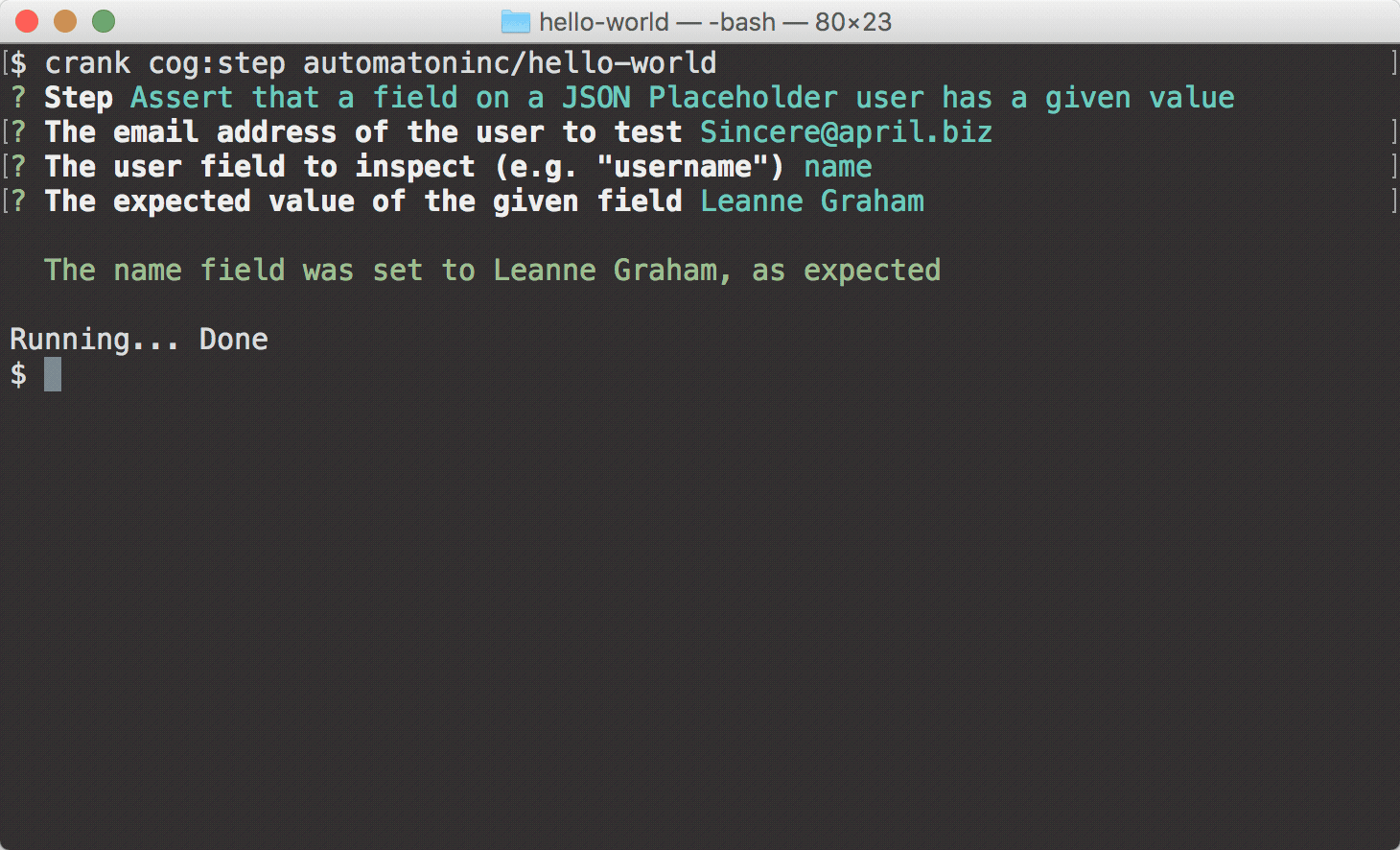
Here are some combinations you can use to see how crank cog:step behaves
according to the values in the API:
Passing Assertion
- User field:
name - Email address:
Sincere@april.biz - Expected value:
Leanne Graham
Failing Assertion
- User Field:
id - Email address:
Shanna@melissa.tv - Expected value:
42
Assertion with Error
- User Field:
subscription - Email address:
Shanna@melissa.tv - Expected value:
premium
Note: scaffolded Cogs include scaffolded automated tests, which you can run to
validate that your Cog is working as expected. The command to run tests will
vary by programming language, so check the generated README.md file for
details.
Replacing the API Client
Replacing the API Client
// ./src/client/client-wrapper.ts
import { YourShinyClient } from 'your-shiny-client';
export class ClientWrapper {
// Declare a static list of required fields here. These will be exposed to
// Crank and other clients via the Cog's GetManifest call.
public static expectedAuthFields: Field[] = [{
field: 'bearerToken',
type: FieldDefinition.Type.STRING,
description: 'Description of field.',
help: 'Optional-but-encouraged help text, e.g. how to get/generate it.',
}];
protected client: YourShinyClient;
// When RunStep or RunSteps is invoked, a new ClientWrapper instance will be
// instantiated with GRPC Metadata. Retrieve your required auth details here.
constructor (auth: grpc.Metadata) {
// And authenticate your API Client by retrieving auth details here.
const apiToken = auth.get('bearerToken').toString();
this.client = new YourShinyClient({ token: apiToken });
}
}
You will almost certainly want to use an API client specific to the system that you're building the Cog for, not a generic HTTP client, as is included by default in the scaffolded code. The generated code includes a generic client only in order to define an opinionated way to use API clients.
The specific steps for replacing the default HTTP client with your own client will vary according to the language used to scaffold the Cog, but generally, you will only need to make modifications in a single file, the Client Wrapper.
You will want to uninstall or otherwise remove the default API client packages, then make changes to the following portions of the Client Wrapper:
- The expectedAuthFields static list should be updated to reflect the details necessary to authenticate your API client (this could include fields like bearer tokens, API endpoints, usernames, passwords, etc). These will be included in the Cog's manifest.
- For strongly typed languages, be sure to update the client property to reflect the signature of your API client.
- Update the Client Wrapper's constructor so that the fields you defined on
expectedAuthFieldsare read and passed to your API Client in order to authenticate it.
Note that if you modify the expected auth fields, you will need to run the
crank registry:rebuild command in order for Crank to pick up your changes.
Using the client wrapper in steps
Adding New Public Methods
// ./src/client/client-wrapper.ts
export class ClientWrapper {
// Any public method here is available on the client on each step class
public async getObjectById(id: Number) {
return this.client.object.findOne(id);
}
}
// ./src/steps/some-step.ts
export class SomeStep {
async executeStep(step: Step): Promise<RunStepResponse> {
const objectId: Number = step.getData().toJavaScript().objectId;
const response = await this.client.getObjectBydId(objectId);
}
}
Rather than passing and using your API client directly in each step, the generated code passes the Client Wrapper to each step. We recommend you keep as much API-specific logic as possible in the wrapper, and instead expose a very simple API to your steps using public methods on the Client Wrapper itself.
This ensures that if your underlying API client changes dramatically, or you need to replace it again, you can do so with edits in just a single file.
Modifying Steps: Static Details
Modifying static step definition details
import { BaseStep, Field, StepInterface } from '../core/base-step';
import { StepDefinition } from '../proto/cog_pb';
// In scaffolded typescript code, the step class name is the Step ID.
export class ClassNameIsTheStepId extends BaseStep implements StepInterface {
// Other static details are protected properties on the class.
protected stepName: string = 'This is the Step Name';
protected stepType: StepDefinition.Type = StepDefinition.Type.VALIDATION;
protected stepExpression: string = 'capture groups (?<nameOfExpectedField>\d+) like so';
protected expectedFields: Field[] = [{
field: 'nameOfExpectedField',
type: FieldDefinition.Type.NUMERIC,
description: 'Description of this field',
help: 'Optional-but-encouraged help text about this field.',
}];
}
Generated code will vary by language, but making changes to steps is similar,
at least in principle, regardless of language: a step is treated as best as
possible like a plugin, including both static details (that define the step and
are used by the Cog to generate the CogManifest), as well as the dynamic,
executable code needed to run assertions (when invoked via RunStep or
RunSteps).
Static details to be aware of as you add or modify steps include:
- Step ID: An external identifier used by Crank and other Cog clients to invoke a particular step. Your Cog will also use this to route/dispatch the step to the right class/plugin/function/executor.
- Step Name: A user-facing string describing the purpose of the step.
- Step Type: A constant indicating whether the step is an action or a validation. You should categorize your step as a validation if your step is best described as an assertion (and is idempotent). Steps which are used to change the state of the underlying system should be categorized as actions.
- Step Expression: An ECMAscript-compatible regular expression used to identify, parse, and package step data for your step in scenario files.
- ExpectedFields: Defines a list of fields and their types (among other details) that your step requires to run.
For further details, check the StepDefinition and FieldDefinition protocol buffer message reference sections.
Note: updates to static portions of a step (e.g. the step ID, name, expression, expected fields, or even net-new steps) are cached at Cog install-time and are not automatically picked up as they are added and modified.
You will need to run crank registry:rebuild in order for Crank to notice
updates to static aspects of steps and step definitions.
Modifying Steps: Test Data
Retrieving test data from a step
import { Step } from '../proto/cog_pb'
// ...
async executeStep(step: Step) {
// Use .toJavaScript() to convert the protobuf Struct to a plain object.
const stepData: any = step.getData().toJavaScript();
const anExpectedField: string = stepData.nameOfExpectedField;
// ...
}
As you add/update/remove expected fields on your step, you will need to extract this new data in your step execution logic. Step data is contained on the data property of a Step, in the form of a Struct. Each language has its own way of accessing this struct; you may wish to transform it into a friendlier, native format for convenience.
The field names / keys on this struct correspond to the field keys you define
on the step definition's expected field(s). The values will be serialized on
the wire as the appropriate Value message according to the type
you defined on the expected field definition. If you specify the type as MAP
or ANYNONSCALAR, the value itself will be a Struct.
We don't recommend or necessarily support nesting of Structs below the first
level.
Modifying Steps: Test Results
Setting an outcome and message on a step response
import { RunStepResponse } from '../proto/cog_pb'
import { Value } from 'google-protobuf/google/protobuf/struct_pb';
// ...
async executeStep(step: Step) {
const response: RunStepResponse = new RunStepResponse();
// Use the RunStepResponse.Outcome enum when setting an outcome.
response.setOutcome(RunStepResponse.Outcome.PASSED);
response.setMessageFormat('Step passed with argument: %s');
// Use Value.fromJavaScript() to easily create the Value.
response.setMessageArgs([Value.fromJavaScript('string argument')]);
return response;
}
The logic about when a step passes, fails, or results in an error is up to you, but you must always respond with the result of your step! A response consists of basically three properties:
- An Outcome, which is either
PASSED,FAILED, orERROR(you must take care to always return aRunStepResponsewith outcomeERROR, rather than a gRPC error, which is not used formally by Crank). - A Message Format, which is a format string (similar to something you'd
pass to
printf-like functions) that explains the outcome of the step in plain English (suitable for display to an end-user). Acceptable replacement tokens are%s(for strings),%d(for integers and floats), and%%for printing a single percent sign. - And Mesage Args, which is a list of replacement values to be used when
formatting the aforementioned message. Each item in this list should be a
protocol buffer
Value.
Note: Unlike static details of a step (e.g. its definition), the actual
code that is executed when a step is run will be picked up automatically with
each crank cog:step or crank cog:steps command invocation. There's no need
to rebuild the registry for these types of changes.
Modifying Steps: Result Records
Adding data records to a step response
import { RunStepResponse, StepRecord } from '../proto/cog_pb'
import { Value } from 'google-protobuf/google/protobuf/struct_pb';
// ...
async executeStep(step: Step) {
const response: RunStepResponse = new RunStepResponse();
// ...
// Instantiate a record, giving it an ID and a name.
const record: StepRecord = new StepRecord();
record.setId('UniqID');
record.setName('Human Readable Name');
// Add data related to the result of this step to the record.
record.setKeyValue(Struct.fromJavaScript({
value1: 'Some value',
anotherOne: 123,
}));
// Add the record to the response.
response.addRecords(record);
// Note: if the name of this cog were someorg/somecog, the above
// step response would result in Dynamic Tokens like this:
// {{somecog.UniqID.value1}} -> "Some Value"
// {{somecog.UniqID.anotherOne}} -> 123
//
// If the step outcome was not passing, a 2-column table would be
// printed, Object Keys to the left and Values to the right.
return response;
}
In the course of executing a step, you might have a lot of useful contextual information at your disposal that could make debugging a result easier for the end user, or be useful in subsequent steps.
You can expose this data to Crank and end-users using Step Records, which come in various flavors depending on the type of data you want to expose.
Some examples:
- When checking a field on an object in a remote system, you might have to load the whole object. End-users might find other fields/values on the object useful in investigating why the Scenario failed.
- When creating a new object in a remote system, an identifier may be assigned and returned at run-time that can be useful in referencing in future steps.
- When building an integration that uses headless browsing technology, it might be useful to capture and return a screenshot of the browser window at the moment a step failed.
If your intention is to only provide extra data to help users solve problems uncovered by failed Scenarios, then adding one or more records to a Step Response (as shown in this example) is sufficient.
If, however, you wish to expose this extra metadata, regardless of the step outcome, for use as Dynamic Tokens, you will additionally want to define the list of Expected Record Definitions on the StepDefinition.
Adding a Cog Step
Adding a new step
// To add a step in scaffolded typescript code, simply add a new Step class
// in the src/steps folder and the Cog will recognize it automatically.
// It may be easiest to duplicate an existing step as a starting point.
Depending on the nature of the language used to scaffold the Cog, the process for adding a step will vary. Specifics instructions are provided here on a language-by-language basis.
Don't forget to run crank registry:rebuild so that Crank recognizes the
new step.
Uninstalling the Cog
You can always uninstall your cog by running a command like the following:
crank cog:uninstall name-of/your-cog. This will not impact the code you've
written so far, but will make Crank forget that your Cog exists, and remove
any/all authentication details associated with your Cog.
You can always manually install a Cog that you are developing locally by
running crank cog:install --source=local and answering the interactive
prompts.
Cog Style Guide
In order to keep the experience of building and using Cogs as consistent and intuitive as possible, we strongly recommend you adhere to the following style guide for user-facing strings in your Cogs.
In general, you are a human, people who use your Cogs and build scenarios
on top of them are human, and the robots only come in after the Cog and the
scenarios are all built and written. As such, avoid using robot words like
assert or validate or print whenever possible.
Instead, try to find friendlier words (that still make sense in the context of
your Cog) like check or show.
In addition to this general advice, here are some specific recommendations for the various user-facing strings you will expose in your Cogs.
Step Expressions
Step expressions are the most important part of your Cog's step definitions. They effectively form an API that users rely on (as a user, you wouldn't want your scenario file to suddenly stop working), so it's important to get your step expression right in the beginning.
In addition to the technical requirements associated with step expressions, you should also keep in mind the following:
Action Steps
# Expression shouldn't include BDD keywords
Bad: `When I navigate to (?<webPageUrl>.+)`
Better: `navigate to (?<webPageUrl>.+)`
# Action expression should start with verb
Bad: `marketo email (?<emailId>\d+) is sent to (?<emailAddr>.+)`
Better: `send marketo email (?<emailId>\d+) to (?<emailAddr>.+)`
- Global Uniqueness: You must ensure that your expressions are globally unique, and would not be ambiguous with step expressions from other Cogs. An easy way to do this is to include the system/service your Cog integrates with in the expression text.
- Case: Your expressions should be lowercase. This is just for consistency, as expressions are evaluated without respect to case (case insensitively).
- In Context: It's useful to imagine how your step would be used in a
typical scenario. Try using your step's expression with a few key prefixes
like
Given I,When I,Then,And,But. Your step should make sense, and as a corollary, should never include these keywords.
Action Steps
Steps that are defined as actions should almost always start with a verb that
corresponds to the action being taken, e.g. create, trigger, add, set,
etc.
Validation Steps
# Use the "should" keyword (and avoid robot words)
Bad: `assert (?<count>\d+) emails? in the inbox`
Better: `there should be (?<count>\d+) emails? in the inbox`
# Global uniqueness, and exclude BDD keywords,
Bad: `then the (?<field>.+) lead field should be (?<value>.+)`
Better: `the (?<field>.+) lead field should be (?<value>.+) in marketo`
Validation Steps
Steps that are defined as validations should almost always take the form
[subject of validation] should [condition of validation], or some variation
of that phrase, including a should keyword.
Step Names
Step Names
# Include helpful keywords (e.g. "fill" and "form")
Bad: `Enter value into field`
Better: `Fill out a form field`
# Avoid sounding robotic
Bad: `Assert email subject text`
Better: `Check email subject line`
Although step names do not represent an API contract with your users, they are still an important way for users to find your step as they write scenarios. Keep this, and the general "users are humans" advice in mind.
Field Descriptions
Field Descriptions
# Simplify
Bad: `Value to enter into the given field`
Better: `Field Value`
# Concise, but specific enough to understand/use
Bad: `DOM Query Selector of the button to be clicked`
Better: `Button's DOM Query Selector`
# Remove detail provided by context
Bad: `SalesForce Client ID`
Better `Client ID`
Again, field descriptions (on either expected fields on step definitions or authentication fields on the Cog manifest itself) do not constitute an API, but they are important wayfinders that can improve user experience when written thoughtfully.
Field descriptions are often used as field labels in constrained interfaces
(e.g. on the CLI when running crank cog:step), so maximizing meaning while
minimizing length is important.
Field descriptions are always displayed in-context (including the step name for a step field, or the Cog label for an authentication field), so unlike step expressions, there's no need to include that context in your field description.
Note for authentication specifically, you can provide a link to help
documentation on the Cog manifest auth_help_url property. This will be shown
to users who attempt to run your Cog without proper authentication.
Protocol Buffer Reference
The following is a reference guide to all message types in the Cog protocol buffer specification, including documentation on how to use the generated code for supported languages.
CogManifest
CogManifest methods
import { CogManifest } from './proto/cog_pb';
// ...
const manifest: CogManifest = new CogManifest();
// Set the Cog's basic details.
manifest.setName('my-org/my-cog');
manifest.setLabel('My Cog')
manifest.setVersion('1.0.0');
// Add a single step definition (type StepDefinition)
manifest.addStepDefinitions(singleStepDefinition);
// Set all step definitions at once (type StepDefinition[])
manifest.setStepDefinitionsList(manyStepDefinitions);
// Add a single auth field (type FieldDefinition)
manifest.addAuthFields(singleAuthField);
// Set all auth fields at once (type FieldDefinition[])
manifest.setAuthFieldsList(manyAuthFields);
// Other helpful metadata.
manifest.setHomepage('https://github.com/my-org/my-cog');
manifest.setAuthHelpUrl('https://github.com/my-org/my-cog/blob/master/README.md#authentication');
The CogManifest represents metadata about your Cog. The details that you include in your CogManifest are used by Cog clients (like Crank) to run, interact with, and otherwise present your Cog. Key properties include:
Name: The globally unique name of your Cog. Should match this Cog's docker image name if you intend to distribute it on docker hub.
An Example:my-org/my-system-cogLabel: A human-friendly label for your Cog. Should most likely be the name of the underlying system that your Cog connects to.
An Example:My SystemVersion: The version of your Cog. Should adhere to semenatic versioning standards and reflect a corresponding docker image tag.
An example:1.0.0.Homepage: An URL representing the homepage for your Cog. Can be the Cog's GitHub or other source control page, Docker Hub page, etc.
Auth Help URL: An optional documentation URL where users can find further details about how to authenticate this Cog.
Step Definitions: A list of steps your Cog can run, including descriptions of data required by each step to run. Order does not matter. Each step in the list should be an instance of StepDefinition
Auth Fields: A list of fields your Cog expects to be passed as metadata on each
RunSteporRunStepscall. Order does not strictly matter, but may be used when prompting users for credentials. Each field in the list should be an instance of FieldDefinition
Note: Cog Manifest details are retrieved and cached when your Cog is first
installed. Any subsequent updates to Cog metadata would only be picked up after
re-installation or after running crank registry:rebuild.
StepDefinition
StepDefinition Methods
import { StepDefinition } from './proto/cog_pb';
// ...
const stepDefinition: StepDefinition = new StepDefinition();
// Set the step definition's ID, name, expression, and help text (all strings)
stepDefinition.setStepId('AssertValueOfMySystemField');
stepDefinition.setName('Assert the Value of a Field');
stepDefinition.setExpression('the MySystem (?<fieldName>.+) field should have value (?<expectedValue>.+)');
stepDefinition.setHelp('This step uses the MySystem API to read field values, and make sure they are as expected.');
// Set the step's type (using an enum)
stepDefinition.setType(StepDefinition.Type.ACTION);
// The other option is StepDefinition.Type.VALIDATION
// Add a single expected field (type FieldDefinition)
stepDefinition.addExpectedFields(singleFieldDefinition);
// Add all expected fields at once (type FieldDefinition[])
stepDefinition.setExpectedFieldsList(manyFieldDefinitions);
// Add any expected records (optional).
stepDefinition.addExpectedRecords(singleExpectedRecordDef);
stepDefinition.setExpectedRecordsList(manyRecordDefinitions);
A step represents an action, assertion, or validation that can be run against a system, e.g. creating an object, asserting that a field on an object has a certain value, printing the contents of an object, or triggering an event or action in a system.
The details provided on a StepDefinition are used by Cog clients (like Crank) to run your Cog's specific steps. A step definition consists of:
Step ID: A unique identifier representing a particular step. This will be passed back as the
Step.step_idon the Step passed to yourRunStep(s) implementation. Use it to dispatch step-specific logic in response to aRunStepRequest.
Note: Once defined, this should almost never be modified; if modified, the change should be accompanied by a major-version change on yourCogManifest.version.
An example:AssertValueOfMySytemFieldName: A human-readable name for this step. This may be used as a way to represent this step to users in a UI or CLI, and may be shown in step run logs.
An example:Assert the Value of a FieldType: Categorizes this step as either an action or a validation. An action is generally assumed to have no
FAILEDstate, onlyPASSEDandERRORstates. A validation is generally assumed to be idempotent and can result in aPASSED,FAILED, orERRORstate.Expression: A string that can be evaluated as an ECMAScript-compatible regular expression. This is used to identify and evaluate this step in cucumber-like scenario files. We recommend following this style guide.
You must use named regex capture groups whose names correspond to keys on theexpected_fieldsfield definitions defined on this step. Never use strict regex position identifiers (e.g.^or$).
Note: Once defined, this should almost never be modified; if modified, the change should be accompanied by an appropriate (e.g. major version) change to yourCogManifest.version.
An example:the MySystem (?<fieldName>.+) field should have value (?<expectedValue>.+)Help: An optional (but encouraged) string that plainly explains what the step does and how it can/should be used. If provided, this value may be surfaced to users in documentation.
Expected Fields: A list of field definitions that this step needs in order to run. The key of each expected field will be used as a key on the map/dictionary passed on
Step.dataon aRunStepRequest. You should have one field for each named capturing group you included in theexpression, but may also include fields not represented in the expression (e.g. for non-scalar data required by your step).
Each item in the list should be of type FieldDefinition.Expected Records: A list of record definitions that this step may respond with alongside other step response data. The definitions provided here are used by Cog clients (like crank) to auto-generate step documentation, as well as provide dynamic token value substitution hints during the Scenario authoring process.
Each item in the list should be of type RecordDefinition
StepDefinition Enums
Type
ACTION: Indicates that this step performs an action.VALIDATION: Indicates that this step performs a validation (e.g. an assertion).
FieldDefinition
FieldDefinition methods
import { FieldDefinition } from './proto/cog_pb';
// ...
const expectedField = new FieldDefinition();
// Set the field's key (a string)
expectedField.setKey('expectedValue');
// Set the field's type (using the corresponding enum)
expectedField.setType(FieldDefinition.Type.ANYSCALAR);
// Set the optionality of the field (using the related enum)
expectedField.setOptionality(FieldDefinition.Optionality.REQUIRED);
// Provide a useful description for humans.
expectedField.setDescription('The value used when making the assertion.');
// Provide useful help text, also for humans, mostly for documentation.
expectedField.setHelp('Does not have to be provided when operator is "is set"');
A field definition represents metadata about a field that your Cog expects in order to run. Field definitions can be applied to both Steps (to define what data is required by the step itself to run) as well as the Cog itself (to define what authentication details are required for your Cog to run any steps at all).
Field definitions consist of the following properties:
Key: The unique identifier for this field. This key will be used when a Cog client (like Crank passes data to your Cog.
If this field represents an expected field on aStepDefinition, this will be used as the key on theStep.dataStruct. If this field represents an authentication field on the Cog itself, it will be the key used to set metadata on the gRPC call.
An example:mySystemAuthTokenOptionality: The optionality of this field (either optional or required). The value should correspond to the equivalent item in the Optionality enum.
Type: This field's type, used by Cog clients (like Crank) to infer validation rules and UX when presenting your Cog and steps to users. It may also be used when serializing data that is passed to your Cog in
RunStep(s) requests. Value should correspond to the equivalent item in the Type enum.Description: The description of this field. This may be used by Cog clients (like Crank) to help users understand what the field is and how it will be used.
An example:Token used to authenticate to MySystemHelp: An optional (but encouraged) string that adds additional context about the field. If the field is used as an Authentication Field, it might explain how to find the field value in the system. If the Field is used on a Step Definition, it could be used to clarify its use or intention.
FieldDefinition Enums
Optionality
OPTIONAL: Indicates that this field is optional.REQUIRED: Indicates that this field is required.
Type
ANYSCALAR: This field represents any scalar value (useful when applied to field expectations with unknown types).STRING: This field represents a string value.BOOLEAN: This field represents a boolean value.NUMERIC: This field represents any type of numeric value (int, float, etc).DATE: This field represents a date (and will be passed as an ISO 8601 date)DATETIME: This field represents a date/time (and will be passed as an ISO 8601 date/time in UTC, with no timezone offset data).EMAIL: This field represents an email address (and will be passed as a string).PHONE: This field represents a phone number (and will be passed as a string)URL: This field represents a URL.ANYNONSCALAR: This field represents any non-scalar value (and will be passed as a Struct protocol buffer message).MAP: This field represents a map (or dictionary or associative array or arbitrary key-value pair), conceptually like a JSON object. It will be passed as a Struct over the wire.
RunStepRequest
RunStepRequest methods
import { Step, RunStepRequest, RunStepResponse } from './proto/cog_pb';
// ...
async runStep(
call: grpc.ServerUnaryCall<RunStepRequest>,
callback: grpc.sendUnaryData<RunStepResponse>,
) {
// Retrieve the step from call.request (RunStepRequest)
const step: Step = call.request.getStep();
// Other contextual identifiers can be pulled like this.
const requestId: string = call.request.getRequestId();
const scenarioId: string = call.request.getScenarioId();
const requestorId: string = call.request.getRequestorId();
}
A RunStep Request is a simple message, passed as the sole argument to your
RunStep (or as a stream to RunSteps) method(s). It consists of a Step
property, as well as three string identifiers, signifiying the "scope" of a
particular request, which could be used for caching, or to otherwise treat
Step runs discriminately.
- Step: This is the Step that your Cog should run; use this step to route or dispatch the request to the appropriate step executor / logic.
- RequestId: Represents a string identifier that your Cog or step execution
code can use to help understand the context of a request or as part of a
cache key. For steps run via the
RunStep(unary) method, this value will be different for every step. For steps run via theRunSteps(streaming) method, this value will be the same across all step requests for a single stream. - ScenarioId: Represents a string identifier whose value will be the same for every step on a single scenario run, but will differ across scenarios when run in the same session (e.g. when a folder of scenarios is run). If the same scenario is run twice, but via separate run invocations, this ID will be different for each run.
- RequestorId: Represents a string identifier whose value will be the same for every step on every scenario run by a given requestor. This value will be the same, even between separate run invocations.
Step
Step methods
// Get the Step ID from the step.
const stepId: string = step.getStepId();
// Convert the step's data to a plain JS object via Struct.toJavaScript()
const stepData: any = step.getData().toJavaScript();
// Pass these details to a theoretical dispatcher.
await dispatchStep(stepId, stepData);
This represents a Step to be run by your Cog, including the data necessary to run your step. It should correspond to a Step Definition that you provided on your CogManifest.
Steps consist of two properties:
Step ID: A string identifying your step; this should correspond to the Step ID of a step definition that you returned in your CogManifest. Use this to route or dispatch a
RunStep(s) invocation to the right handler.Data: This is an arbitrary package of data your step needs to run. It corresponds to a map/dictionary of field values that align to the expected fields you provided on the corresponding StepDefinition.
This is represented as a Google Protocol Buffer Struct, whose keys map to those you provided on the expected fields property of this step and whose values are represented as Values.
Struct and Value objects may be cumbersome to work with natively in your preferred language, so you may want to transform these into equivalent native types for convenience.
RunStepResponse
RunStepResponse methods
import { Step, RunStepResponse } from '../proto/cog_pb';
// ...
async executeStep(step: Step): Promise<RunStepResponse> {
const response: RunStepResponse = new RunStepResponse();
if (everythingPassed) {
// Set the outcome using the appropriate enum value
response.setOutcome(RunStepResponse.Outcome.PASSED);
response.setMessageFormat('Successfully asserted %s');
// Add a single message arg like this:
response.addMessageArgs(Value.fromJavaScript('assertion'));
} else {
response.setOutcome(RunStepResponse.Outcome.FAILED);
response.setMessageFormat('Step failed because: %s');
// Set all message args at once, like this:
response.setMessageArgsList([Value.fromJavaScript('reasons')]);
}
return response;
}
This represents the response you send to the Cog client (e.g. Crank) once your
Step has finished running (on RunStep and as a stream on RunSteps methods).
You should always return a RunStepResponse, even when there is an underlying
error in your code or code your Cog depends on.
Outcome: The outcome of this step (passed, failed, or error). Value should correspond to one of the packaged Outcome enums.
Message Format: A message format, similar to a string suitable for use in
printf-like functions, that represents the outcome of this step. This message (and supplied arguments below) may be used by Cog clients like Crank in step run logs. You should vary this message according to the outcome of the step.
Acceptable replacement tokens are:%s(for strings),%d(for numeric values of any kind), and%%(as a way to print a single percent sign).
An example:Expected MySystem field %s to have value %s, but it was actually %sMessage Args: An optional list of arguments to be applied to the message format, used as replacement tokens in the message format (like
printf).
RunStepResponse Enums
Outcome
PASSED: Indicates that this step completed successfully.FAILED: Indicates that this step completed, but did not meet expectations.ERROR: Indicates that this step could not be completed due to an error.
StepRecord
StepRecord methods
import { RunStepResponse, StepRecord } from '../proto/cog_pb';
// ...
async executeStep(step: Step): Promise<RunStepResponse> {
const response: RunStepResponse = new RunStepResponse();
const record: StepRecord = new StepRecord();
record.setId('RecordId');
record.setName('Name of Record');
// Use one (and only one) of the following to set data on the record.
record.setKeyValue(/* */);
record.setTable(/* */);
record.setBinary(/* */)
response.addRecords(record);
return response;
}
This represents a piece of structured data that may be included on a Step Response. Cog clients (like crank) will render this structured data in order to help users diagnose failures or errors. This data also forms the basis for dynamic token value substitution.
- ID: A unique identifier (alphanumeric) for this record. It should
correspond to the id on the corresponding RecordDefinition that you provide
on the StepDefinition message. A common example would be
lead. - Name: Represents a human-readable name or description of this record,
which may be displayed along with the record value by Cog clients (like
crank). A common example would be
The Lead Record That Was Checked.
The actual data that is stored and transmitted on the Step Record may take one of three forms, and are stored on the following properties:
- KeyValue: Takes the form of a
Struct. In Scenario Run output, this will be printed as a two-column table. It may also be used as the basis for Dynamic Token values. - Table: Takes the form of a TableRecord. Will be printed as a table with as many columns as are provided. It may also be used as the basis for Dynamic Token values.
- Binary: Takes the form of a BinaryRecord. Will be written to a temporary location on disk, and a link to the corresponding file will be printed. This can only be used for Scenario Run output, and will have no impact on Dynamic Tokens.
Note: One StepRecord instance may only contain one type of data. If you need
to return more, you may specify more than one record on the Run Step Response.
RecordDefinition
RecordDefinition methods
import { RecordDefinition } from './proto/cog_pb';
// ...
const expectedRecord = new RecordDefinition();
// Set the ID (corresponding to the ID of the eventual StepRecord)
expectedRecord.setId('lead');
// Set the type of data that Cog clients should expect.
expectedRecord.setType(RecordDefinition.Type.KEYVALUE);
// Set one (of potentially many) guaranteed fields.
expectedRecord.addGuaranteedFields(someExpectedFieldDefinition);
// If there may be more fields than the guaranteed fields given, set to true.
expectedRecord.setMayHaveMoreFields(true);
This represents the definition of a StepRecord's schema. Metadata provided here informs Cog clients (like crank) of what records to expect and what form they will take. This metadata is used to improve step documentation and enable dynamic token hinting in the Scenario authoring process.
ID: A unique identifier (alphanumeric) for this record. It should correspond to the id on the StepRecord that is provided on the
RunStepResponsemessage. A common example:lead.Type: The type of record (key/value, table, or binary). The value should correspond to one of the packaged Type enums.
Guaranteed Fields: Represents a list of fields (
FieldDefinitions) whose keys are guaranteed to be included on the Record's key/value object or in every table row. This list should be reserved for fields which will always be included (e.g. the ID or creation date of a Lead object). Note: this field is only relevant forStepRecordsof typeKEYVALUEorTABLE.May Have More Fields: Set this to
trueif the list of Guaranteed Fields provided on this record definition is non-exhausitve (meaning: the record may contain additional fields, but their keys and types are unknowable until run-time). Note: only relevant for StepRecords of typeKEYVALUEorTABLE.
RunStepResponse Enums
Type
KEYVALUE: Indicates the record will contain a Map/Object of data.TABLE: Indicates the record will contain tabular data.BINARY: Indicates the record will contain binary data.
TableRecord
TableRecord methods
import { TableRecord } from './proto/cog_pb';
// ...
const tableRecord = new TableRecord();
// Set table headers.
tableRecord.setHeaders(Struct.fromJavaScript({
code: 'Error Code',
name: 'Error Name',
msg: 'Error Message',
}));
// Set table data.
tableRecord.addRows(Struct.fromJavaScript({
code: 401,
name: 'Incorrect Password',
msg: 'Re-authenticate and try again.',
}))
tableRecord.addRows(Struct.fromJavaScript({
code: 500,
name: 'Server Error',
msg: 'The server was unable to respond.',
}))
This represents a type of structured data record that a RunStepResponse may
include. This record type is useful when you want to represent data which is
multi-dimensional (e.g. has many rows/columns). In these situations, it's
recommended to use this record type, rather than returning many instances of
the Struct or Key/Value record type.
Headers: A key/value map (
Struct) representing table headers. Each key should correspond to a key on each provided row, while the value represents the label shown to the user as the column header when rendered.Rows: Represents the actual table rows to be rendered (another
Struct).
BinaryRecord
BinaryRecord methods
import { BinaryRecord } from './proto/cog_pb';
// ...
const binaryRecord = new BinaryRecord();
// Set the proper mimetype.
binaryRecord.setMimeType('image/png')
// Set the raw data.
binaryRecord.setData(Buffer.from('...', 'base64'));
Represents a type of structured data record that a RunStepResponse may
include. This record type is useful for large, binary objects like images,
flat files, or documents.
Data: The binary data itself, represented as protobuf
bytes.MimeType: A mime type that describes how the data can or could be rendered, e.g.
image/png. Note: when the file is written to disk, the value of the latter part of the type (in this example,png) will be used as the file extension when saving the file to disk.
FAQ
Why gRPC and protocol buffers?
Engineers who write and maintain automated tests for their applications often
have the luxury of using a test framework written in the same language as the
application itself (e.g. mocha for JavaScript apps, pytest for Python,
phpunit for PHP, etc).
Because Crank expands the test domain to include any application, we decided to build the system using gRPC, enabling the use of any language to implement test steps and assertions for a given system, regardless of the breadth and makeup of the developer community and ecosystem around it.
It seems like this could lead to a lot of API calls. What do?
Yes, if you build a Cog with a Step that checks an object by hitting an API endpoint, and an end-user writes a Scenario that uses the step several times in succession, without special care, you will execute just as many requests against the system's API endpoint.
Crank provides some useful metadata (Contextual IDs) that can be used to reduce overall API usage by caching some API response data in memory. Check the RunStepRequest protocol buffer documentation for details.
Is there a tool like Postman, but for interacting with gRPC services?
Yes! But the experience is less than ideal, especially when trying to encode
data in the Struct and Value protocol buffer message formats that Cog
leverages. Nevertheless, it's a good tool for sanity checking your Cog, and
it's also open source, so you could contribute back usability improvements too.
Check out BloomRPC.
Business users don't typically know how to work on the commandline, and they definitely don't do a lot of coding. How does Crank make it easy for them to validate their workflows?
We can't make it easy for business users without first making it easy for engineers! We won't be able to address the massive quality and reliability gap in complex SaaS technology stacks without an open ecosystem and community focused on solving the problem.